[TOC]
层次聚类 Hierarchical-Clustering
场景
随着网络技术的发展,我们迎来了信息爆炸的时代。我们都知道现代大数据有4个特点:
- 体量大 Volume
- 高速化 Velocity
- 多样化 Variety
- 低价值密度 Value
未经处理的数据信息之间的联系往往较低,体量大而价值密度低。为了更好地挖掘数据价值,一个思路是找到数据之间的相似点进行度量和聚类,将数据点进行聚类,获得关联以更好地利用数据。网络世界中的推荐算法就是数据应用的一个典型例子。如淘宝、京东、拼多多等购物平台的商品推荐页面,谷歌、百度等搜索引擎的推荐回答,网易云音乐的日推歌曲……高效的推荐算法可以帮助我们快速的从体量庞大的信息流中定位到我们需要的有价值的数据,一定程度上便利了我们的生活。
推荐算法如何能实现推荐我们感兴趣的内容呢?我们往往会发现这样一个事实:品味相似的人会对相似的事物感兴趣。由此衍生出的一个思路是从相似的人出发:如找到兴趣爱好相同的两个人A和B,便可以将A感兴趣的内容推荐给B,由此推广到整个社区类群。在实际应用中,有协同过滤算法基于用户历史数据对用户进行群组划分并在此基础上推荐相似的物品,挖掘用户潜在兴趣。
在协同过滤中实现聚类有较多方法,本实验选择自底向上的层次聚类进行复现。
原理
先明确我们要实现什么:我们有一些离散的无关联的数据点,想要衡量它们之间的相似度,并以此为准则进行聚类。
那么这就要解决2个问题:
- 相似度如何定义?
- 如何评估聚类的效果?
首先,关于相似度定义的问题,需要定义一个函数来进行样本距离的衡量。如:
- Single-Linkage最短距离法:取两个类中距离最近的两个样本的距离作为两个集合的距离。
- Complete-Linkage最长距离法:取两个集合中距离最远的两个点的距离作为两个集合的距离。
- Average-linkage中间距离法:取两两距离的平均值作为两个集合之间的距离。
- 类平均法:取两两距离的中值作为两个集合之间的距离。
四种方法各有特点:
- 最短距离法相对限制较少,最终会得到一个相对松散的社群。
- 最长距离法相对限制较大。一个问题是:有可能两个类群已经很接近了,但由于单个样本的干扰便没有合并。
- 最短距离和最长距离法这考虑了某个有特点的数据,而没有考虑类内数据的整体特点,时间复杂度相对较低。
- 类平均法与取均值相比更能消除个别偏离样本对结果的干扰。
其次,关于聚类效果评估的问题。容易发现,聚类和分类是不同的。对于分类问题,我们已经有了正确的标签,因此分类问题是一个有监督的学习。而聚类本身没有一个“正确”的结果,是一种无监督的学习。因为聚类没有一个确定的答案,目前尚未有一个效果较好的的评测指标评价聚类效果,更多的是靠数据可视化和人工评测效果。
层次聚类有两种思路:
- 自底向上的凝聚法:凝聚法指的是初始时将每个样本点当做一个类簇,然后依据相似度合并这些初始的类簇,直到达到某种条件或者达到设定的分类数目。
- 自顶向下的分裂法:初始时将所有的样本归为一个类簇,然后依据相似度进行逐渐的分裂,直到达到某种条件或者达到设定的分类数目。
特点
优点
- 距离度量函数可以任意定义,较为灵活。
- 层次聚类结果是一个树状图,包含关系结构清晰,一个结点可以属于多个类。
- 一次性获得整个聚类树,可以直接根据需要对聚类树进行横向切割获得指定数量的类簇。
缺点
- 计算复杂度大
- 贪心算法获得局部最优,不一定是全局最优解。
- 层次聚类具有不可逆性,一旦聚类结果形成,想要就不能重新合并来优化聚类性能。
- 对于不同的问题,需要人为选择合适的距离度量函数、终止条件和参数。
实现步骤
- 移除网络中的所有边,得到有 n 个孤立节点,每个节点作为一个集合。
- 两两计算相似度
- 根据选取相似度最小的两个结点进行合并
- 重复2和3直到满足条件终止,形成树状图
- 根据实际需求横切树状图,获得聚类的社区结构
代码执行
依赖
1 | python==3.8.8 |
代码实现
导入库
1 | # 导入库 |
导入数据
1 | # 导入数据集 |
数据预处理
1 | # 数据集预处理 |
层次聚类树状图
1 | plt.figure(figsize=(20, 6)) |
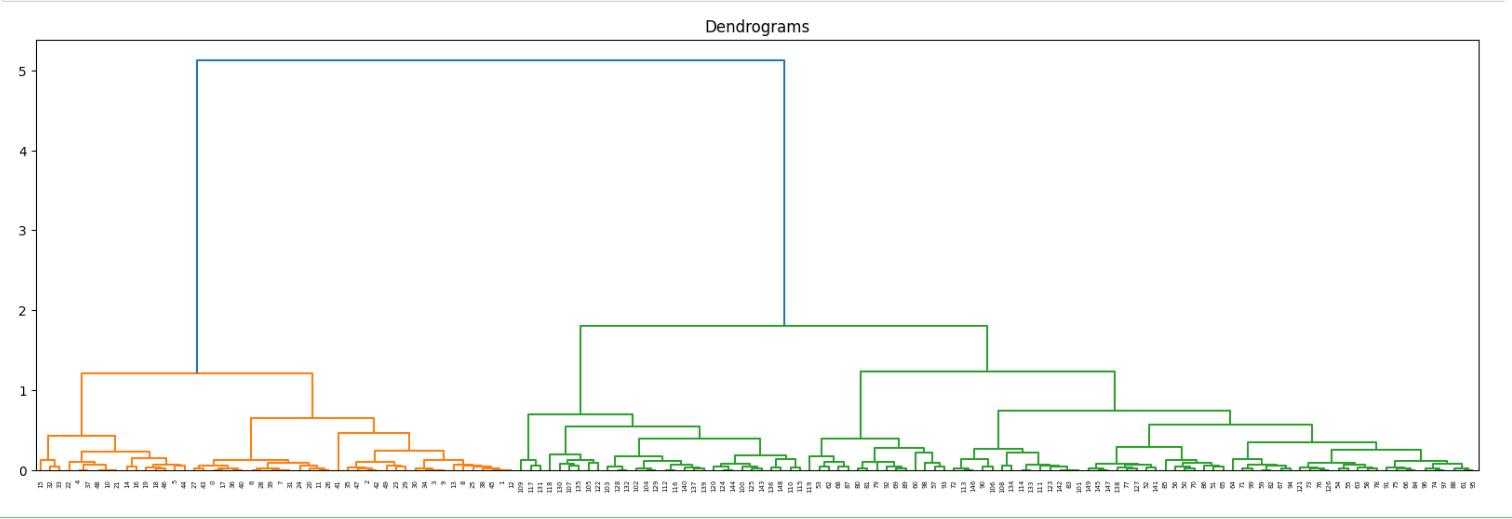
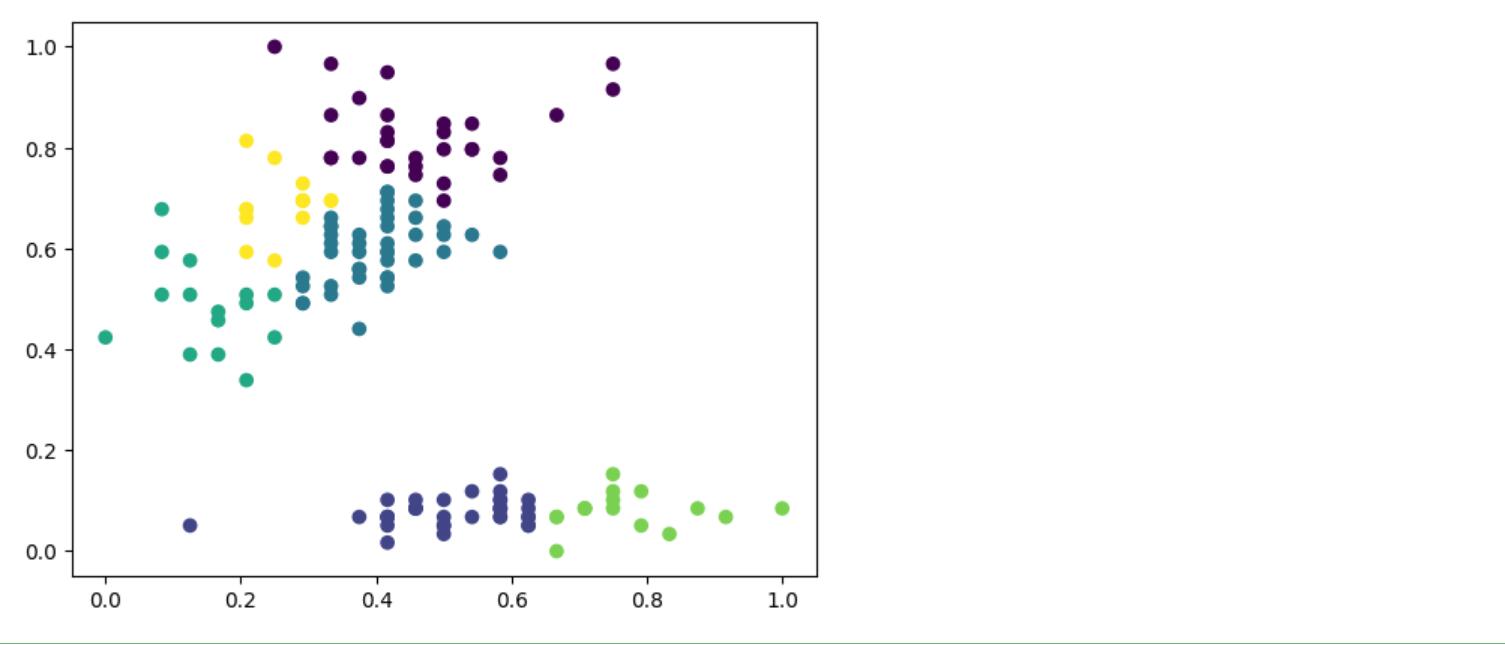
层次聚类分布图
1 | # ward:集合间距离等于两类对象之间的最小距离。(即最短距离法single-linkage聚类) |