Source:
论坛网站The 7th Lecture
可信人脸识别分析
引入
发展历程
邓教授将人脸识别技术发展分为以下四个阶段:
- 第一阶段是以PCA、LDA等为代表的全局性学习方法。把人脸图像视为特征向量,对变换后的特征向量进行模式分类。
- 第二阶段针对图像特点手工设计局部滤波器去学习与光线无关的局部特征,比前一类方法更鲁棒,但是无法应对光影明暗的变化。代表方法是LBP。
- 第三阶段引入机器学习来设计滤波器,所获得的特征不再是手工设计的,而是由机器自动学习出的具有辨别力的特征。
- 第四阶段将深度学习引入到人脸识别领域,性能大幅提升。其中,深度网络提取特征的过程与人类识别人脸的过程相似。早期的block提取图像的边缘信息,随着网络深度的增加,后期的block提取人脸中更高级的特征属性。
概述
人脸识别作为一个经典问题,在现代生活中应用场景十分广泛。
- 1:1身份认证
- 1:n比对排查
人脸识别是一个特殊的分类问题。因为每个人就是一个类,地球上人口众多,对应类别也很多,所以常常采用0样本学习的方法,在小数据上学习人脸的特征,然后迁移到更大的数据场景下应用。
人的脸部可以包含两种信息:
- (表)身份identity
- (里)表情、情绪、内心
之前对于表情的研究,更多把表情视为离散而独立的6个类。而后来发现,表情特征是一个连续空间上的变化。
精准性
良好的准确性是可信可靠的基础。在海量的人脸数据下,要想提高识别的精确度,面临两个问题:
- 噪声的处理和过滤(很多图片的质量比较低)
- 实现无监督的学习(有许多无标注的数据)
噪声处理
Long tailed learning
将数据分为head data和tail data,不同质量的数据,采用不同的处理方法,完成一个双流的训练过程
- 对于head data,正常用来训练模型,提高模型性能。
- tail data 数据量小且包含噪声。对于长尾、噪声数据,为其设计特殊的训练损失函数(基于度量学习),降噪以提高鲁棒性。
SFace-Method
实验表明,若不特殊降噪处理,有时去掉tail data反而模型性能会上升。原因之一是模型overfit噪声导致性能下降,因此特别处理噪声数据,调整损失函数,利用sigmoid对梯度进行加权,屏蔽小梯度,提高模型鲁棒性。
Dynamic Training Data Dropout
正常数据和噪声数据(标签错误)在训练过程中往往表现出不同的状态。噪声大往往优化慢,数据特征和标签之间的余弦相似度更小。由此可以从整个训练过程来观察,动态剔除拖慢训练的噪声数据。
数据增广
神经网络的训练实际上是拟合现在的数据分布,如果数据集不够庞大多样,那么再好的训练方法也只是拟合一个“错误”的分布,不能很好地提高模型性能。而人工标注的数据代价又十分高昂(拼不过企业),则考虑自动化收集和标注数据,自动进行数据增强。
Close loop of data labeling and model training
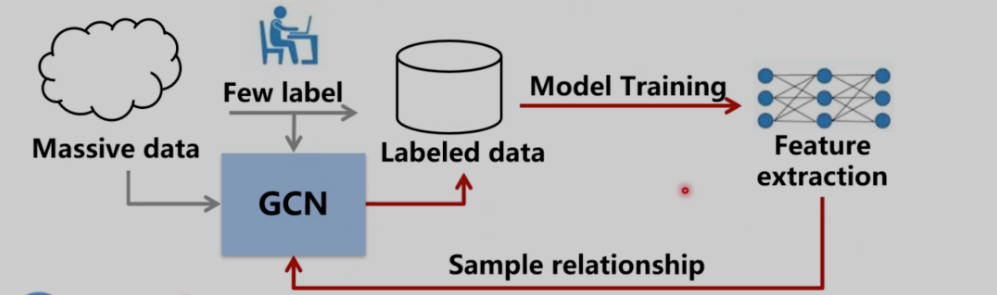
- 使用少量已标记数据集预训练出一个基本的特征模型
- 让GCN学习到同类图像的特征之间的关系
- 将大量无标注数据输入到GCN,GCN可以自动判断这些数据的标签。
GCN相当于一个过滤器,massive data经过GCN后成为labeled data。
前提:初始状态好(机器效果已经和人差不多了),经过迭代之后更强。
鲁棒性
negative pairs: similar looking
positive pairs: cross-aging, cross-poses…
归一
针对姿态变化的图像,设计归一化网络,归一化为正面图像(也可以归一化不同角度,借此来进行数据增强…)
低分辨率
对于低分辨率的数据集,一种思路是利用SR超分辨率解决方法,提高数据集,但过高的分辨率往往会导致overfit。他们的实验表明,在人脸识别中,直接学习低分辨率的图片反而分类效果会更好。
- 设计MR-GAN生成低分辨率图像,用于模拟监控所拍摄到的低分辨率图像。
- 运用跨步迁移,让高分辨和低分辨图像的特征分别靠近中间域,最终可以得到融合后的特征。
安全性
物理:硅胶面具(教授说还没解决,有时候这个连人都能骗过。但他自己的一篇工作rPPG“人脸的心跳”感觉可以解决一点?)
如果我们只基于现在的数据,那就只能预防过去的攻击,自然而然想到进行数据增广,提高泛化能力(学到未来的造假方式)
Representative Forgery Mining For Fake Face Detection
根据注意力机制可以了解机器关注的fake face特征,利用随机遮挡把这个特征去掉,可以迫使机器寻找更多假脸特征,而不是只找到一个假脸原因就摆烂。
rPPG
一点生物学知识,部分光线会透过皮肤到达血管,血管会有反射信号,则视频中呈现的人脸有“心跳”信号。而假脸则无,由此可以借助真脸与假脸关于rPPG信号的差别来构造网络。
问题:
- 缺少数据
- 攻击知道这个特征后,也可以人为构造有rPPG信号的假脸。
迁移攻击
迁移攻击场景下,代理模型和远端模型越相似,则攻击成功率也一般相应越高。一个思路是,对本地模型多次使用dropout,模拟不同模型架构,根据本地模型构建一个具有更高泛化能力的对抗样本。
这样构建出的对抗样本往往具备更好的迁移性和泛化性,还可以用来做数据增强,进行对抗训练。
防
对于对抗攻击,比较好的防御方法(目前相对)是对抗训练。
局限:
- 滞后性。先有攻后有防。
- 对于小模型小数据,对抗训练会降低准确率。
公平性
公平性是个容易引发争议的伦理问题,但是对于公平性缺乏完善的评价指标。
数据偏见
不同数据集,人种、地域占比数量不同。对比度低往往容易受到噪声的影响,所以肤色不同客观上会导致一些结构不同。
但是他们经过实验,公平的数据集不一定可以获得好的结果,说明公平性还有其它影响因素。
算法偏见
神经网络设计目标函数(损失函数)是为了提高精确性、鲁棒性等。如果往其中加入公平性的约束,可以取得比较好的效果。在实际的工作中,他们给不同的人种应用不同的参数,最终模型呈现出一个良好的公平性结果。
邓教授分别利用强化学习、元学习、迁移学习等消除bias
迁移学习
不同数据集之间存在bias,有时分辨图片来自哪个数据集的准确率甚至高于图片本身的分类结果。一个思路是采用迁移学习实现原域到目标域的转换。
Q&A
人脸识别上的对抗攻防
- 对抗防御没有好方法,只有对抗训练
- 对抗攻击在人脸上研究不多,因为人脸是一个零样本问题,而非分类问题。
表情
问题:
- 没有好的数据集
- 主观性强
- 相对来说效果有待提高